
Yapay Zekayı Kendi Verilerimizle Konuşturmak: RAG ve Vektör Veritabanları
Selamlar! Bugün, yapay zeka dünyasında taşları yerinden oynatan ve özellikle biz geliştiriciler için LLM'leri (Large Language Models) çok daha işlevsel hale getiren bir mimariyi masaya yatırıyoruz: RAG (Retrieval-Augmented Generation).
Eğer daha önce bir sohbet botu geliştirdiyseniz veya ChatGPT gibi modellerle çalıştıysanız, en büyük kısıtlamayı fark etmişsinizdir: Model, sadece eğitildiği tarihe kadar olan verileri bilir. Peki ya biz ona kendi PDF'lerimizi, teknik dökümanlarımızı veya veritabanımızdaki güncel bilgileri "öğretmek" istersek? İşte burada devreye sihirli bir formül giriyor.
RAG Nedir?
RAG, basitçe özetlemek gerekirse; bir yapay zeka modeline soru sormadan hemen önce, o soruyla ilgili bilgileri kendi veri kaynaklarımızdan bulup (Retrieval), modele bu bilgilerle birlikte "Bak, cevap burada, bu bağlama göre yanıtla" (Augmented) deme sürecidir.
Yani modeli yeniden eğitmek (fine-tuning) yerine, ona bir açık kitap sınavı veriyoruz. Kitap bizim verilerimiz, öğrenci ise LLM.
İşin Kalbi: Vektör Veritabanları
Peki, binlerce döküman arasından sorumuzla en alakalı olanı milisaniyeler içinde nasıl buluyoruz? Klasik SELECT * FROM posts WHERE content LIKE '%...%' sorguları burada maalesef sınıfta kalıyor. İşte burada Vektör Veritabanları sahneye çıkıyor.
Vektörleştirme (Embedding) Nedir?
Bilgisayarlar kelimeleri anlamaz, sayıları anlar. Bir metni alıp onu matematiksel bir uzayda koordinatlara (vektörlere) dönüştürme işlemine Embedding diyoruz.
Örneğin: "Kedi" ve "Köpek" kelimeleri bu matematiksel uzayda birbirine yakınken, "Ekran Kartı" kelimesi bambaşka bir köşededir.
Neden Standart Veritabanı Değil?
Vektör veritabanları, verileri kelime eşleşmesine göre değil, anlamsal yakınlığa göre arar. Siz "Hava çok sıcak" diye arattığınızda, içinde bu kelimeler geçmese bile "Güneş yakıyor" cümlesini bulup getirebilir.
Kullandığım bazı popüler araçlar:
- Supabase Vector (PostgreSQL tabanlı olduğu için entegrasyonu çok kolay)
- Pinecone
- ChromaDB
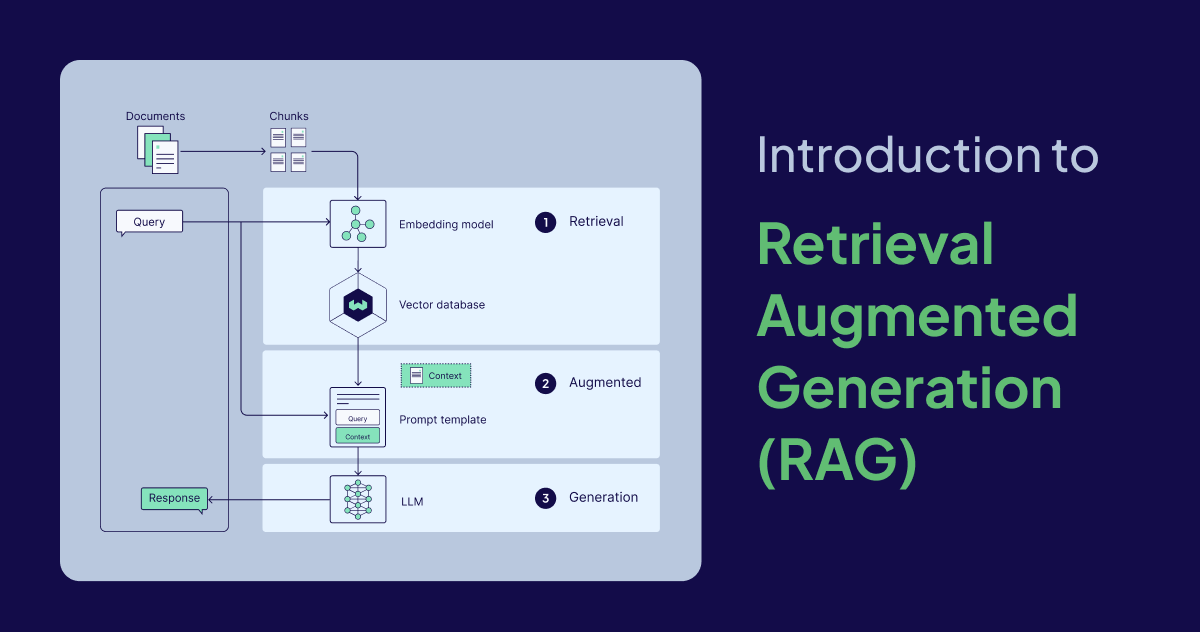
RAG Süreci Nasıl İşler?
Bir RAG sistemini kurarken genellikle şu 5 adımı takip ediyoruz:
- Veri Hazırlığı: Elimizdeki dökümanları küçük parçalara (chunks) bölüyoruz.
- Embedding: Bu parçaları bir embedding modeli (örn:
text-embedding-3-small) ile vektörlere dönüştürüyoruz. - Depolama: Vektörleri bir Vektör Veritabanına kaydediyoruz.
- Sorgulama: Kullanıcı bir soru sorduğunda, soruyu da vektöre çevirip veritabanındaki en yakın parçaları buluyoruz.
- Cevap Üretimi: Bulunan parçaları ve soruyu LLM'e (GPT-4 vb.) gönderip anlamlı bir cevap alıyoruz.
Örnek Bir Sorgu Mantığı
Basit bir JavaScript örneğiyle süreci hayal edelim:
// Kullanıcının sorusunu vektöre çevir
const queryVector = await getEmbeddings(userInput);
// Vektör veritabanında benzer dökümanları ara
const { data: documents } = await supabase.rpc('match_documents', {
query_embedding: queryVector,
match_threshold: 0.8,
match_count: 5,
});
// Bulunan dökümanları LLM'e context olarak ver
const prompt = `
Aşağıdaki bilgilere dayanarak soruyu cevapla:
${documents.map(d => d.content).join('\n')}
Soru: ${userInput}
`;Sonuç: Neden RAG Öğrenmeliyiz?
Gelecekte yazılım projelerinin çoğu, hazır yapay zekaları kendi özel verilerimizle özelleştirmek üzerine kurulu olacak. RAG mimarisi sayesinde:
- Modeli eğitmek için binlerce dolar harcamıyoruz.
- Verilerimiz güncellendiğinde sadece veritabanını güncellemek yeterli oluyor.
- Yapay zekanın "uydurma" (hallucination) ihtimalini minimuma indiriyoruz.
Teknoloji yığınınızda bir vektör veritabanına yer açmanın vakti geldi de geçiyor bile! Bir sonraki yazıda görüşmek üzere.