
Making AI Speak with Our Own Data: RAG and Vector Databases
Greetings! Today, we're discussing an architecture that's shaking things up in the world of AI and making LLMs (Large Language Models) much more functional, especially for us developers: RAG (Retrieval-Augmented Generation).
If you've ever developed a chatbot or worked with models like ChatGPT, you've probably noticed the biggest limitation: the model only knows data up to the date it was trained. But what if we want to "teach" it our own PDFs, technical documents, or up-to-date information from our database? That's where a magic formula comes in.
What is RAG?
To summarize simply, RAG is; Before asking an AI model a question, we retrieve information related to that question from our own data sources (Retrieval) and then, using this information, we tell the model, "Look, the answer is here, respond according to this context" (Augmented).
In other words, instead of retraining (fine-tuning) the model, we give it an open-book exam. The book is our data, and the student is the LLM.
The Heart of the Matter: Vector Databases
So, how do we find the most relevant document to our question among thousands of documents in milliseconds? Classic SELECT * FROM posts WHERE content LIKE '%...%' queries unfortunately fail here. This is where Vector Databases come into play.
What is Vectorization (Embedding)?
Computers don't understand words, they understand numbers. The process of taking a text and transforming it into coordinates (vectors) in a mathematical space is called Embedding.
For example: While the words "Cat" and "Dog" are close to each other in this mathematical space, the word "Graphics Card" is in a completely different corner.
Why Not a Standard Database?
Vector databases search data based on semantic proximity, not word matching. When you search for "It's very hot," it can find and retrieve the phrase "The sun is burning" even if those words aren't present.
Some popular tools I use:
-
Supabase Vector (Very easy to integrate because it's PostgreSQL based)
How Does the RAG Process Work?
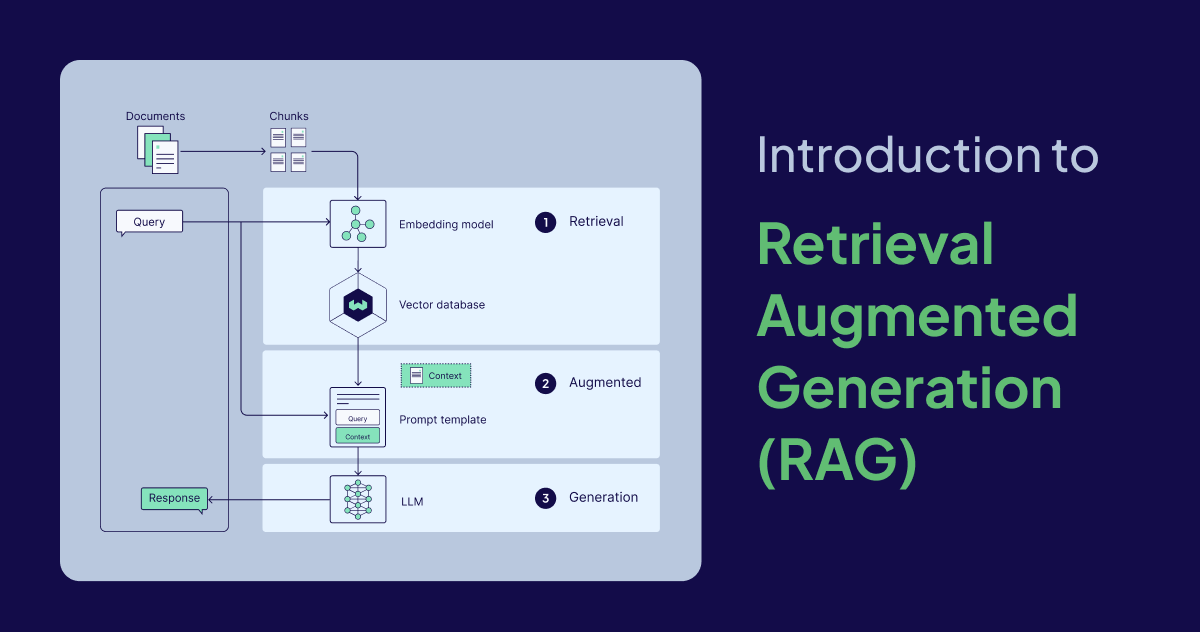
When setting up a RAG system, we generally follow these 5 steps:
- Data Preparation: We break down the available documents into smaller chunks.
- Embedding: We convert these chunks into vectors using an embedding model (e.g.,
text-embedding-3-small). - Storage: We save the vectors to a Vector Database.
- Querying: When a user asks a question, we convert the question into a vector and find the closest chunks in the database.
- Answer Generation: We send the found chunks and the question to the LLM (GPT-4, etc.) and receive a meaningful answer.
An Example Query Logic
Let's imagine the process with a simple JavaScript example:
// Convert the user's query to a vector
const queryVector = await getEmbeddings(userInput);
// Search for similar documents in the vector database
const { data: documents } = await supabase.rpc('match_documents', {
query_embedding: queryVector,
match_threshold: 0.8,
match_count: 5,
});
// Provide the found documents to the LLM as context
const prompt = `
Answer the question based on the following information:
${documents.map(d => d.content).join('\n')}
Question: ${userInput}
`;Conclusion: Why Should We Learn RAG?
Most software projects in the future will be based on customizing ready-made AIs with our own specific data. Thanks to the RAG architecture:
- We don't spend thousands of dollars training the model.
- When our data is updated, it is enough to only update the database.
- We minimize the possibility of AI "hallucinating" (hallucination).
It's high time you made room for a vector database in your technology stack! See you in the next article.